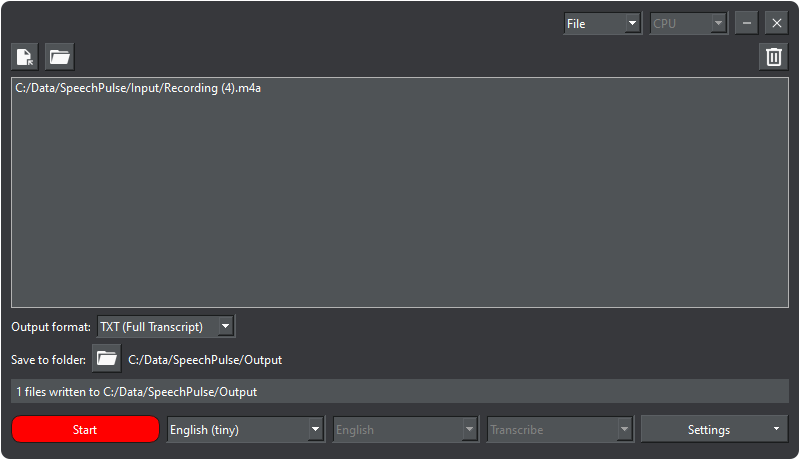
SpeechPulse - converts audio into text
SpeechPulse uses neural network to convert audio files or voice recorded from a microphone into text.
This application interested me as soon as I saw it. Unlike the currently popular large language models, like ChatGPT, which are used to create content for you, this app just helps you translate your thoughts into text. Many people find it easier to come up with text by speaking it rather than typing it. And while there have been voice recognition apps, the quality of the recognition has always left a lot to be desired. In theory, the development of neural networks was supposed to improve the situation. Let's see if this is the case.
The SpeechPulse distribution kit has a rather impressive size - 1.25GB. And it contains only the basic language models for English. Installing each additional model will require another 1-2GB of disk space, plus another gigabyte to support processing on Nvidia graphics cards. This is not a small amount, but in this case it's justified. All this volume is useful data.
The application can work in two modes:
1. You specify a list of audio files and start their processing. The result is saved in text files in the directory you specify.
2. The application processes the data received from your microphone in real time and types the recognized text into the currently active application. This can be notepad, browser or any other application that supports keyboard input.

I tested both modes using a paragraph from one of my previous posts. It started with the words "The program's interface looks ascetic". First, I recorded it three times to audio files using the Windows Voice Recorder application, and then I also spoke into the microphone three times using Live mode in SpeechPulse. Each time I tried to read at the same speed and intonation. The results were very different.
In the first mode all three files were recognized in a few seconds, with almost the same result and very close to the original. In the second mode, the word "ascetic" was transformed into "static", "identical" and, for some reason, even, "particular". Obviously, the application does not manage the microphone very efficiently. If the sound recorded with Voice Recorder can be listened, to confirm that the voice sounds clear and loud, how and what SpeechPulse "hears" is unknown. Unfortunately, the program doesn't provide any options to adjust the microphone.
The second problem with Live mode is that the program takes a very long time to "enter" anything into the active application. You can read out a whole paragraph, then wait another 10 seconds and only then the text appears. In addition, I tried two different microphones and with one of them the text sometimes didn't appear at all. This behavior is confusing. Instead of thinking about what to say, you have to think about whether the data will be saved.
I read the website of the Wisper neural network used in the app. It says that "Input audio is split into 30-second chunks." I.e. apparently, the input delay is due to the peculiarities of the neural network architecture and this limitation can't be bypassed. In this case, it would be nice to have some indication in the application that data collection is in progress and new text chunk will be available in N seconds. It would also be nice if the recognized text could be entered not only in the active application, but also in some field in SpeechPulse itself and/or written to the log file. Just in case you forget to make the right application active or accidentally change it while thinking.
Saving the audio stream to a file would be nice too. That way, the user would be sure that in an emergency they could listen to the recording and type the text manually.
In the meantime, recording an audio file using a third-party application and then recognizing it with SpeechPulse is a pretty decent, though not the most convenient, option.
Tags
ai
Recent Posts

Scroll to Top